A simple example of semantic segmentation with tensorflow keras
This post is about semantic segmentation. This is the task of assigning a label to each pixel of an images. It can be seen as an image classification task, except that instead of classifying the whole image, you’re classifying each pixel individually. From this perspective, semantic segmentation is actually very simple. Let’s see how we can build a model using Keras to perform semantic segmentation.
This tutorial is posted on my blog and in my github repository where you can find the jupyter notebook version of this post.
We’re going to use MNIST extended, a toy dataset I created that’s great for exploring and playing around with deep learning models. In this post, we won’t look into how the data is generated, for more information on that, you can checkout my post : MNIST Extended: A simple dataset for image segmentation and object localisation
In this post I assume a basic understanding of deep learning computer vision notions such as convolutional layers, pooling layers, loss functions, tensorflow/keras etc.
Import packages
Let’s start by importing a few packages. I’ve printed the tensorflow version we’re importing. We’ll only be using very simple features of the package, so any version of tensorflow 2 should work.
import tensorflow as tf
print(tf.__version__)
import numpy as np
print(np.__version__)
import matplotlib
from matplotlib import pyplot as plt
print(matplotlib.__version__)
2.0.0
1.19.1
3.3.1
Semantic segmentation dataset
from simple_deep_learning.mnist_extended.semantic_segmentation import create_semantic_segmentation_dataset
If you’re running the code yourself, you might have a few dependencies missing. You can either install the missing dependencies yourself, or you can pip install the requirements file from the github repository. It’s also possible to install the simple_deep_learning package itself (which will also install the dependencies). Checkout the README.md in the github repository for installation instructions.
np.random.seed(1)
train_x, train_y, test_x, test_y = create_semantic_segmentation_dataset(num_train_samples=1000,
num_test_samples=200,
image_shape=(60, 60),
max_num_digits_per_image=4,
num_classes=3)
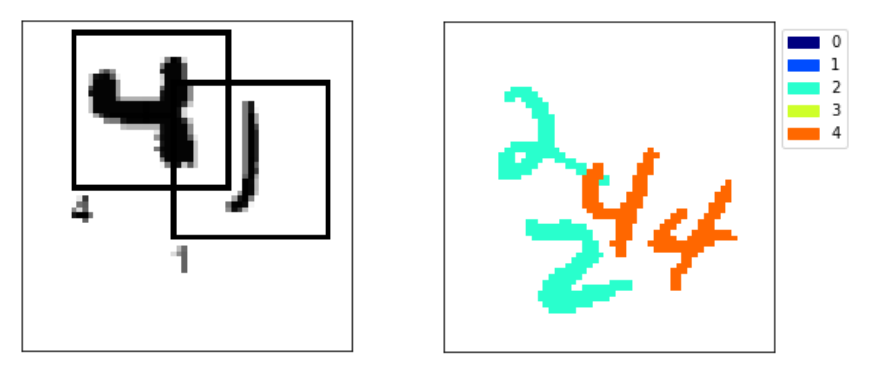
Let’s take a quick look at what this input and output looks like.
import numpy as np
from simple_deep_learning.mnist_extended.semantic_segmentation import display_grayscale_array, plot_class_masks
print(train_x.shape, train_y.shape)
i = np.random.randint(len(train_x))
display_grayscale_array(array=train_x[i])
plot_class_masks(train_y[i])
(1000, 60, 60, 1) (1000, 60, 60, 3)

I’ve printed the shapes of the train inputs and targets. As expected the input is a grayscale image. The output is slightly strange however, it’s essentially a grayscale image for each class we have in our semantic segmentation task. Here we chose num_classes=3 (i.e digits 0, 1 and 2) so our target has a last dimension of length 3. If this is strange to you, I strongly recommend you check out my post on the MNIST extended where I explain this semantic segmentation dataset in more detail.
Semantic segmentation modelling
Model architecture
This post is part of the simple deep learning series. My objective here is to achieve reasonably good results with a simple model. This helps understand the core concepts related to a particular deep learning task. It’s then very possible to gradually include components from state of the art models to achieve better results or a more efficient model.
Before I give you the simplest model architecture for semantic segmentation, I’d like you to spend a bit of time trying to imagine what that would be.
Need help? I’ll give you a hint. For semantic segmentation, the width and height of our output should be the same as our input (semantic segmentation is the task of classifying each pixel individually) and the number of channels should be the number of classes to predict.
The simplest model that achieves that is simply a stack of 2D convolutional layers! It’s that simple. If you’re familiar with image classification, you might remember that you need pooling to gradually reduce the input size on top of which you add a dense layer. For semantic segmentation this isn’t even needed because your output is the same size as the input! This very simple model of stacking convolutional layers is called a Fully Convolutional Network (FCN).
Let’s see whether this is good enough. We’ll be using tf.keras’s sequential API to create the model.
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
tf.keras.backend.clear_session()
model = models.Sequential()
model.add(layers.Conv2D(filters=16, kernel_size=(3, 3), activation='relu', input_shape=train_x.shape[1:], padding='same'))
model.add(layers.Conv2D(filters=32, kernel_size=(3, 3), activation='relu', padding='same'))
model.add(layers.Conv2D(filters=32, kernel_size=(3, 3), activation='relu', padding='same'))
model.add(layers.Conv2D(filters=32, kernel_size=(3, 3), activation='relu', padding='same'))
model.add(layers.Conv2D(filters=32, kernel_size=(3, 3), activation='relu', padding='same'))
model.add(layers.Conv2D(filters=32, kernel_size=(3, 3), activation='relu', padding='same'))
model.add(layers.Conv2D(filters=32, kernel_size=(3, 3), activation='relu', padding='same'))
model.add(layers.Conv2D(filters=32, kernel_size=(3, 3), activation='relu', padding='same'))
model.add(layers.Conv2D(filters=32, kernel_size=(3, 3), activation='relu', padding='same'))
model.add(layers.Conv2D(filters=16, kernel_size=(3, 3), activation='relu', padding='same'))
model.add(layers.Conv2D(filters=train_y.shape[-1], kernel_size=(3, 3), activation='sigmoid', padding='same'))
We’re not going to bother ourselves with fancy activations, let’s just go with relu for the intermediate layers and sigmoid for the last layer. I chose sigmoid for the output because it produces and activation between 0 and 1 (i.e a probability) and our classes are non exclusive, otherwise we could use a softmax along the channels axis.
“Same” padding is perfectly appropriate here, we want our output to be the same size as our input and same padding does exactly that.
I’m not going to claim some sort of magical intuition for the number of convolutional layers or the number of filters. When experimenting for this article, I started with an even smaller model, but it wasn’t managing to learn anything. So I gradually increased the size until it started learning.
I’ve got a deep learning hint for you. If you’re ever struggling to find the correct size for your models, my recommendation is to start with something small. If that small model isn’t managing to fit the training dataset, then gradually increase the size of your model until you manage to fit the training set. Unless you’ve made a particularly bad architectural decision, you should always be able to fit your training dataset, if not, your model is probably too small.
Let’s look at how many parameters our model has.
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 60, 60, 16) 160
_________________________________________________________________
conv2d_1 (Conv2D) (None, 60, 60, 32) 4640
_________________________________________________________________
conv2d_2 (Conv2D) (None, 60, 60, 32) 9248
_________________________________________________________________
conv2d_3 (Conv2D) (None, 60, 60, 32) 9248
_________________________________________________________________
conv2d_4 (Conv2D) (None, 60, 60, 32) 9248
_________________________________________________________________
conv2d_5 (Conv2D) (None, 60, 60, 32) 9248
_________________________________________________________________
conv2d_6 (Conv2D) (None, 60, 60, 32) 9248
_________________________________________________________________
conv2d_7 (Conv2D) (None, 60, 60, 32) 9248
_________________________________________________________________
conv2d_8 (Conv2D) (None, 60, 60, 32) 9248
_________________________________________________________________
conv2d_9 (Conv2D) (None, 60, 60, 16) 4624
_________________________________________________________________
conv2d_10 (Conv2D) (None, 60, 60, 3) 435
=================================================================
Total params: 74,595
Trainable params: 74,595
Non-trainable params: 0
_________________________________________________________________
About 75000 trainable parameters. For reference, VGG16, a well known model for image feature extraction contains 138 million parameters. In comparison, our model is tiny. That’s good, because it means we should be able to train it quickly on CPU.
Let’s choose our training parameters. Adam is my go to gradient descent based optimisation algorithm, I don’t want to go into the details of how adam works but it’s often a good default that I and others recommend.
For the loss function, I chose binary crossentropy. This is a good loss when your classes are non exclusive which is the case here. If your labels are exclusive, you might want to look at categorical crossentropy or something else.
Keras allows you to add metrics to be calculated while the model is training. These don’t influence the training process but are useful to follow training performance. Accuracy is often the default, but here accuracy isn’t very meaningful. Our classes are so imbalanced (i.e a lot more pixels are background than they are digits) that even a model that always predicts 0 will have a great accuracy. For that reason I added recall and precision, those metrics are a lot more useful to evaluate performance, especially in the case of a class imbalance.
I was slightly worried that the class imbalance would prevent the model from learning (I think it does a bit at the beginning) but eventually the model learns.
model.compile(optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(),
metrics=[tf.keras.metrics.BinaryAccuracy(),
tf.keras.metrics.Recall(),
tf.keras.metrics.Precision()])
Train and evaluate
Let’s train the model for 20 epochs. This takes about 11 minutes on my 2017 laptop with CPU only. If you have GPU available, then use it. Your model will train a lot faster (approx 10x speed depending on your GPU/CPU). If you’re familiar with Google Colab then then you can also run the notebook version of the tutorial on there and utilise the free GPU/TPU available on the platform (you will need to copy or install the simple_deep_learning package to generate the dataset).
history = model.fit(train_x, train_y, epochs=20,
validation_data=(test_x, test_y))
Train on 1000 samples, validate on 200 samples
Epoch 1/20
1000/1000 [==============================] - 39s 39ms/sample - loss: 0.2830 - binary_accuracy: 0.9458 - recall: 0.0266 - precision: 0.0711 - val_loss: 0.0752 - val_binary_accuracy: 0.9601 - val_recall: 0.0000e+00 - val_precision: 0.0000e+00
Epoch 2/20
1000/1000 [==============================] - 38s 38ms/sample - loss: 0.0709 - binary_accuracy: 0.9598 - recall: 0.0000e+00 - precision: 0.0000e+00 - val_loss: 0.0641 - val_binary_accuracy: 0.9601 - val_recall: 0.0000e+00 - val_precision: 0.0000e+00
Epoch 3/20
1000/1000 [==============================] - 36s 36ms/sample - loss: 0.0595 - binary_accuracy: 0.9590 - recall: 0.0381 - precision: 0.6183 - val_loss: 0.0568 - val_binary_accuracy: 0.9580 - val_recall: 0.0781 - val_precision: 0.5779
Epoch 4/20
1000/1000 [==============================] - 38s 38ms/sample - loss: 0.0548 - binary_accuracy: 0.9575 - recall: 0.1105 - precision: 0.6330 - val_loss: 0.0527 - val_binary_accuracy: 0.9551 - val_recall: 0.2162 - val_precision: 0.6086
Epoch 5/20
1000/1000 [==============================] - 38s 38ms/sample - loss: 0.0508 - binary_accuracy: 0.9555 - recall: 0.2354 - precision: 0.6553 - val_loss: 0.0486 - val_binary_accuracy: 0.9558 - val_recall: 0.2681 - val_precision: 0.6815
Epoch 6/20
1000/1000 [==============================] - 37s 37ms/sample - loss: 0.0469 - binary_accuracy: 0.9554 - recall: 0.3294 - precision: 0.7167 - val_loss: 0.0447 - val_binary_accuracy: 0.9545 - val_recall: 0.3860 - val_precision: 0.7028
Epoch 7/20
1000/1000 [==============================] - 39s 39ms/sample - loss: 0.0429 - binary_accuracy: 0.9559 - recall: 0.4088 - precision: 0.7670 - val_loss: 0.0404 - val_binary_accuracy: 0.9568 - val_recall: 0.4336 - val_precision: 0.7997
Epoch 8/20
1000/1000 [==============================] - 45s 45ms/sample - loss: 0.0408 - binary_accuracy: 0.9564 - recall: 0.4440 - precision: 0.7983 - val_loss: 0.0384 - val_binary_accuracy: 0.9569 - val_recall: 0.4866 - val_precision: 0.8160
Epoch 9/20
1000/1000 [==============================] - 46s 46ms/sample - loss: 0.0375 - binary_accuracy: 0.9572 - recall: 0.4902 - precision: 0.8368 - val_loss: 0.0371 - val_binary_accuracy: 0.9581 - val_recall: 0.4432 - val_precision: 0.8508
Epoch 10/20
1000/1000 [==============================] - 39s 39ms/sample - loss: 0.0352 - binary_accuracy: 0.9577 - recall: 0.5175 - precision: 0.8581 - val_loss: 0.0364 - val_binary_accuracy: 0.9568 - val_recall: 0.5367 - val_precision: 0.8272
Epoch 11/20
1000/1000 [==============================] - 42s 42ms/sample - loss: 0.0347 - binary_accuracy: 0.9578 - recall: 0.5271 - precision: 0.8666 - val_loss: 0.0345 - val_binary_accuracy: 0.9574 - val_recall: 0.5920 - val_precision: 0.8554
Epoch 12/20
1000/1000 [==============================] - 43s 43ms/sample - loss: 0.0334 - binary_accuracy: 0.9582 - recall: 0.5425 - precision: 0.8822 - val_loss: 0.0332 - val_binary_accuracy: 0.9581 - val_recall: 0.5709 - val_precision: 0.8741
Epoch 13/20
1000/1000 [==============================] - 40s 40ms/sample - loss: 0.0323 - binary_accuracy: 0.9584 - recall: 0.5491 - precision: 0.8882 - val_loss: 0.0351 - val_binary_accuracy: 0.9566 - val_recall: 0.6564 - val_precision: 0.8446
Epoch 14/20
1000/1000 [==============================] - 42s 42ms/sample - loss: 0.0320 - binary_accuracy: 0.9585 - recall: 0.5577 - precision: 0.8914 - val_loss: 0.0316 - val_binary_accuracy: 0.9581 - val_recall: 0.5888 - val_precision: 0.8752
Epoch 15/20
1000/1000 [==============================] - 44s 44ms/sample - loss: 0.0301 - binary_accuracy: 0.9589 - recall: 0.5743 - precision: 0.9084 - val_loss: 0.0329 - val_binary_accuracy: 0.9578 - val_recall: 0.6012 - val_precision: 0.8701
Epoch 16/20
1000/1000 [==============================] - 41s 41ms/sample - loss: 0.0301 - binary_accuracy: 0.9588 - recall: 0.5755 - precision: 0.9048 - val_loss: 0.0298 - val_binary_accuracy: 0.9588 - val_recall: 0.6040 - val_precision: 0.9025
Epoch 17/20
1000/1000 [==============================] - 38s 38ms/sample - loss: 0.0290 - binary_accuracy: 0.9590 - recall: 0.5847 - precision: 0.9143 - val_loss: 0.0295 - val_binary_accuracy: 0.9586 - val_recall: 0.6410 - val_precision: 0.8998
Epoch 18/20
1000/1000 [==============================] - 37s 37ms/sample - loss: 0.0280 - binary_accuracy: 0.9592 - recall: 0.5929 - precision: 0.9206 - val_loss: 0.0301 - val_binary_accuracy: 0.9586 - val_recall: 0.6418 - val_precision: 0.9001
Epoch 19/20
1000/1000 [==============================] - 37s 37ms/sample - loss: 0.0277 - binary_accuracy: 0.9593 - recall: 0.5955 - precision: 0.9240 - val_loss: 0.0280 - val_binary_accuracy: 0.9590 - val_recall: 0.6358 - val_precision: 0.9098
Epoch 20/20
1000/1000 [==============================] - 37s 37ms/sample - loss: 0.0269 - binary_accuracy: 0.9594 - recall: 0.6037 - precision: 0.9294 - val_loss: 0.0271 - val_binary_accuracy: 0.9594 - val_recall: 0.6150 - val_precision: 0.9231
We’ve stopped the training before the loss plateaued, as you can see, both train and validation loss were still going down after 20 epochs which means that some extra performance might be gained from training longer. However we’re not here to get the best possible model.
At the end of epoch 20, on the test set we have an accuracy of 95.6%, a recall of 58.7% and a precision of 90.6%. Remember, these are the metrics for each individual pixel. So the metrics don’t give us a great idea of how our segmentation actually looks. To get a better idea, let’s look at a few predictions from the test data.
test_y_predicted = model.predict(test_x)
from simple_deep_learning.mnist_extended.semantic_segmentation import display_segmented_image
np.random.seed(6)
for _ in range(3):
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(10, 5))
i = np.random.randint(len(test_y_predicted))
print(f'Example {i}')
display_grayscale_array(test_x[i], ax=ax1, title='Input image')
display_segmented_image(test_y_predicted[i], ax=ax2, title='Segmented image', threshold=0.5)
plot_class_masks(test_y[i], test_y_predicted[i], title='y target and y predicted sliced along the channel axis')
Example 138
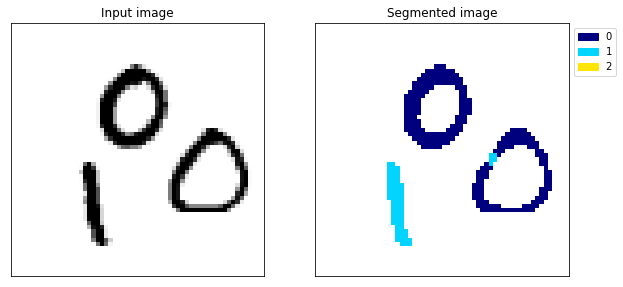

Example 106


Example 109


These randomly selected samples show that the model has at least learnt something. It does quite a good job of detecting the digits but it has some problems. By looking at a few examples, it becomes apparent that the model is far from perfect. In my opinion, this model isn’t good enough. There’s no overfitting the test dataset so we could train for longer, or increase the size of the model but we can do better than that.
Improvements
We can improve our model by adding few max pooling layers. The first benefit of these pooling layers is computational efficiency. By reducing the size of the intermediate layers, our network performs fewer computations, this will speed up training a bit. However, the number of parameters remains the same because our convolutions are unchanged. The problem with adding the pooling layers is that our output will no longer have the same height and width the input image. To solve that problem we an use upsampling layers. These simple upsampling layers perform essentially the inverse of the pooling layer. A (2, 2) upsampling layer will transform a (height, width, channels) volume into a (height * 2, width * 2, channels) volume simply by duplicating each pixel 4 times. By applying the same number of upsampling layers as max pooling layers, our output is of the same height and width as the input.
Another, more intuitive, benefit of adding the pooling layers is that it forces the network to learn a compressed representation of the input image. It’s not totally evident how this helps, but by forcing the intermediate layers to hold a volume of smaller height and width than the input, the network is forced to learn the important elements of the input image as a whole as opposed to simply passing all information through. As you’ll see, the pooling layers not only improve computational efficiency but also improve the performance of our model!
This idea of compressing a complex input to a compact representation and using that representation to construct an output is a very common idea in deep learning, such models are often called “encoder-decoder” models. They’re not only used in computer vision, in this more advanced deep learning post, I explore the use of encoder-decoders for time series prediction.
tf.keras.backend.clear_session()
model = models.Sequential()
model.add(layers.Conv2D(filters=16, kernel_size=(3, 3), activation='relu', input_shape=train_x.shape[1:], padding='same'))
model.add(layers.Conv2D(filters=32, kernel_size=(3, 3), activation='relu', padding='same'))
model.add(layers.MaxPooling2D(pool_size=(2, 2)))
model.add(layers.Conv2D(filters=32, kernel_size=(3, 3), activation='relu', padding='same'))
model.add(layers.Conv2D(filters=32, kernel_size=(3, 3), activation='relu', padding='same'))
model.add(layers.MaxPooling2D(pool_size=(2, 2)))
model.add(layers.Conv2D(filters=32, kernel_size=(3, 3), activation='relu', padding='same'))
model.add(layers.Conv2D(filters=32, kernel_size=(3, 3), activation='relu', padding='same'))
model.add(layers.UpSampling2D(size=(2, 2)))
model.add(layers.Conv2D(filters=32, kernel_size=(3, 3), activation='relu', padding='same'))
model.add(layers.Conv2D(filters=32, kernel_size=(3, 3), activation='relu', padding='same'))
model.add(layers.UpSampling2D(size=(2, 2)))
model.add(layers.Conv2D(filters=32, kernel_size=(3, 3), activation='relu', padding='same'))
model.add(layers.Conv2D(filters=16, kernel_size=(3, 3), activation='relu', padding='same'))
model.add(layers.Conv2D(filters=train_y.shape[-1], kernel_size=(3, 3), activation='sigmoid', padding='same'))
model.compile(optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(),
metrics=[tf.keras.metrics.BinaryAccuracy(),
tf.keras.metrics.Recall(),
tf.keras.metrics.Precision()])
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 60, 60, 16) 160
_________________________________________________________________
conv2d_1 (Conv2D) (None, 60, 60, 32) 4640
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 30, 30, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 30, 30, 32) 9248
_________________________________________________________________
conv2d_3 (Conv2D) (None, 30, 30, 32) 9248
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 15, 15, 32) 0
_________________________________________________________________
conv2d_4 (Conv2D) (None, 15, 15, 32) 9248
_________________________________________________________________
conv2d_5 (Conv2D) (None, 15, 15, 32) 9248
_________________________________________________________________
up_sampling2d (UpSampling2D) (None, 30, 30, 32) 0
_________________________________________________________________
conv2d_6 (Conv2D) (None, 30, 30, 32) 9248
_________________________________________________________________
conv2d_7 (Conv2D) (None, 30, 30, 32) 9248
_________________________________________________________________
up_sampling2d_1 (UpSampling2 (None, 60, 60, 32) 0
_________________________________________________________________
conv2d_8 (Conv2D) (None, 60, 60, 32) 9248
_________________________________________________________________
conv2d_9 (Conv2D) (None, 60, 60, 16) 4624
_________________________________________________________________
conv2d_10 (Conv2D) (None, 60, 60, 3) 435
=================================================================
Total params: 74,595
Trainable params: 74,595
Non-trainable params: 0
_________________________________________________________________
history = model.fit(train_x, train_y, epochs=20,
validation_data=(test_x, test_y))
Train on 1000 samples, validate on 200 samples
Epoch 1/20
1000/1000 [==============================] - 19s 19ms/sample - loss: 0.3355 - binary_accuracy: 0.9403 - recall: 0.0318 - precision: 0.0616 - val_loss: 0.1344 - val_binary_accuracy: 0.9601 - val_recall: 0.0000e+00 - val_precision: 0.0000e+00
Epoch 2/20
1000/1000 [==============================] - 17s 17ms/sample - loss: 0.0972 - binary_accuracy: 0.9598 - recall: 0.0000e+00 - precision: 0.0000e+00 - val_loss: 0.0818 - val_binary_accuracy: 0.9601 - val_recall: 0.0000e+00 - val_precision: 0.0000e+00
Epoch 3/20
1000/1000 [==============================] - 17s 17ms/sample - loss: 0.0773 - binary_accuracy: 0.9598 - recall: 0.0000e+00 - precision: 0.0000e+00 - val_loss: 0.0723 - val_binary_accuracy: 0.9601 - val_recall: 0.0000e+00 - val_precision: 0.0000e+00
Epoch 4/20
1000/1000 [==============================] - 17s 17ms/sample - loss: 0.0694 - binary_accuracy: 0.9598 - recall: 0.0000e+00 - precision: 0.0000e+00 - val_loss: 0.0661 - val_binary_accuracy: 0.9601 - val_recall: 0.0000e+00 - val_precision: 0.0000e+00
Epoch 5/20
1000/1000 [==============================] - 17s 17ms/sample - loss: 0.0648 - binary_accuracy: 0.9598 - recall: 0.0000e+00 - precision: 0.0000e+00 - val_loss: 0.0623 - val_binary_accuracy: 0.9601 - val_recall: 1.3908e-04 - val_precision: 1.0000
Epoch 6/20
1000/1000 [==============================] - 18s 18ms/sample - loss: 0.0599 - binary_accuracy: 0.9597 - recall: 0.0242 - precision: 0.8687 - val_loss: 0.0583 - val_binary_accuracy: 0.9583 - val_recall: 0.1040 - val_precision: 0.6663
Epoch 7/20
1000/1000 [==============================] - 18s 18ms/sample - loss: 0.0541 - binary_accuracy: 0.9581 - recall: 0.1451 - precision: 0.7368 - val_loss: 0.0524 - val_binary_accuracy: 0.9566 - val_recall: 0.2215 - val_precision: 0.6927
Epoch 8/20
1000/1000 [==============================] - 18s 18ms/sample - loss: 0.0502 - binary_accuracy: 0.9578 - recall: 0.1983 - precision: 0.7569 - val_loss: 0.0477 - val_binary_accuracy: 0.9577 - val_recall: 0.2330 - val_precision: 0.7623
Epoch 9/20
1000/1000 [==============================] - 17s 17ms/sample - loss: 0.0474 - binary_accuracy: 0.9573 - recall: 0.2586 - precision: 0.7650 - val_loss: 0.0490 - val_binary_accuracy: 0.9541 - val_recall: 0.3124 - val_precision: 0.6513
Epoch 10/20
1000/1000 [==============================] - 17s 17ms/sample - loss: 0.0464 - binary_accuracy: 0.9563 - recall: 0.3471 - precision: 0.7608 - val_loss: 0.0457 - val_binary_accuracy: 0.9553 - val_recall: 0.4305 - val_precision: 0.7479
Epoch 11/20
1000/1000 [==============================] - 17s 17ms/sample - loss: 0.0397 - binary_accuracy: 0.9576 - recall: 0.4826 - precision: 0.8528 - val_loss: 0.0355 - val_binary_accuracy: 0.9593 - val_recall: 0.4879 - val_precision: 0.9086
Epoch 12/20
1000/1000 [==============================] - 17s 17ms/sample - loss: 0.0346 - binary_accuracy: 0.9585 - recall: 0.5753 - precision: 0.8972 - val_loss: 0.0332 - val_binary_accuracy: 0.9583 - val_recall: 0.5929 - val_precision: 0.8888
Epoch 13/20
1000/1000 [==============================] - 18s 18ms/sample - loss: 0.0308 - binary_accuracy: 0.9592 - recall: 0.6123 - precision: 0.9226 - val_loss: 0.0300 - val_binary_accuracy: 0.9594 - val_recall: 0.5996 - val_precision: 0.9226
Epoch 14/20
1000/1000 [==============================] - 18s 18ms/sample - loss: 0.0283 - binary_accuracy: 0.9596 - recall: 0.6402 - precision: 0.9383 - val_loss: 0.0269 - val_binary_accuracy: 0.9603 - val_recall: 0.6119 - val_precision: 0.9553
Epoch 15/20
1000/1000 [==============================] - 17s 17ms/sample - loss: 0.0258 - binary_accuracy: 0.9600 - recall: 0.6598 - precision: 0.9533 - val_loss: 0.0291 - val_binary_accuracy: 0.9596 - val_recall: 0.6172 - val_precision: 0.9294
Epoch 16/20
1000/1000 [==============================] - 17s 17ms/sample - loss: 0.0256 - binary_accuracy: 0.9601 - recall: 0.6609 - precision: 0.9533 - val_loss: 0.0249 - val_binary_accuracy: 0.9601 - val_recall: 0.7022 - val_precision: 0.9524
Epoch 17/20
1000/1000 [==============================] - 17s 17ms/sample - loss: 0.0243 - binary_accuracy: 0.9603 - recall: 0.6760 - precision: 0.9623 - val_loss: 0.0238 - val_binary_accuracy: 0.9603 - val_recall: 0.7151 - val_precision: 0.9571
Epoch 18/20
1000/1000 [==============================] - 17s 17ms/sample - loss: 0.0230 - binary_accuracy: 0.9605 - recall: 0.6821 - precision: 0.9672 - val_loss: 0.0229 - val_binary_accuracy: 0.9606 - val_recall: 0.6724 - val_precision: 0.9634
Epoch 19/20
1000/1000 [==============================] - 17s 17ms/sample - loss: 0.0223 - binary_accuracy: 0.9605 - recall: 0.6864 - precision: 0.9696 - val_loss: 0.0235 - val_binary_accuracy: 0.9603 - val_recall: 0.7354 - val_precision: 0.9565
Epoch 20/20
1000/1000 [==============================] - 17s 17ms/sample - loss: 0.0223 - binary_accuracy: 0.9605 - recall: 0.6853 - precision: 0.9691 - val_loss: 0.0225 - val_binary_accuracy: 0.9605 - val_recall: 0.7063 - val_precision: 0.9638
Incredibly, this small modification to our model has allowed us to gain 10 percentage points in recall! The training process also takes about half the time.
Let’s see how that looks by displaying the examples we checked earlier.
test_y_predicted = model.predict(test_x)
from simple_deep_learning.mnist_extended.semantic_segmentation import display_segmented_image
np.random.seed(6)
for _ in range(3):
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(10, 5))
i = np.random.randint(len(test_y_predicted))
print(f'Example {i}')
display_grayscale_array(test_x[i], ax=ax1, title='Input image')
display_segmented_image(test_y_predicted[i], ax=ax2, title='Segmented image')
plot_class_masks(test_y[i], test_y_predicted[i], title='y target and y predicted sliced along the channel axis')
Example 138
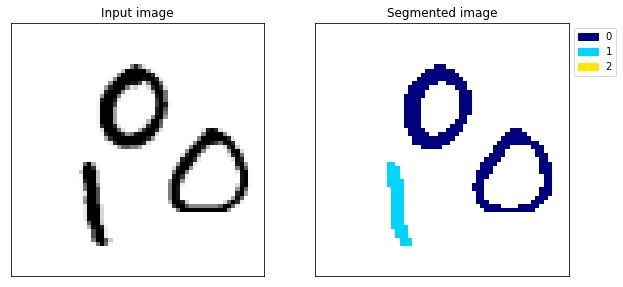

Example 106


Example 109


The difference is huge, the model no longer gets confused between the 1 and the 0 (example 117) and the segmentation looks almost perfect.
Conclusion
State of the art models for semantic segmentation are far more complicated than what we’ve seen so far. What we’ve created isn’t going to get us on the leaderboard of any semantic segmentation competition… However, hopefully you’ve understood that the core concepts behind semantic segmentation are actually very simple. This post is just an introduction, I hope your journey won’t end here and that I have encouraged you to experiment with your own modelling ideas. You could make the ch Perhaps you could look at the concepts that make state of the art semantic segmentation models and try to implement them yourself on this simple dataset. A good starting point is this great article that provides an explanation of more advanced ideas in semantic segmentation.
I hope enjoyed reading this post. If you have any questions or have done something cool with the this dataset that you would like to share, comment below or reach out to me on Linkedin. I love hearing from you.
Have a great day,
Luke