Keras implementation of an encoder-decoder for time series prediction using architecture
I created this post to share a flexible and reusable implementation of an encoder/decoder model for time series prediction using Keras.
I drew inspiration from two other posts:
- “Sequence to Sequence (seq2seq) Recurrent Neural Network (RNN) for Time Series Prediction” by Guillaume Chevalier
- “A ten-minute introduction to sequence-to-sequence learning in Keras” by François Chollet.
I strongly recommend visiting Guillaume’s repository for some great projects.
François Chollet is the primary author and currently the maintainer of Keras. His post presents an implementation of a seq2seq model for machine translation.
All the code for this post can be found on my github page, feel free to download and use it as you wish.
Context
Time series prediction is a widespread problem. Applications range from price and weather forecasting to biological signal prediction.
This post describes how to implement a Recurrent Neural Network (RNN) encoder-decoder for time series prediction using Keras. I will focus on the practical aspects of the implementation, rather than the theory underlying neural networks, though I will try to share some of the reasoning behind the ideas I present. I assume a basic understanding of how RNNs work. If you need to catch up, a good place to start is the classic “Understanding LSTM Networks” by Christopher Olah.
What is an encoder-decoder and why are they useful for time series prediction?
The simplest RNN architecture for time series prediction is a “many to one” implementation.
A “many to one” recurrent neural net takes as input a sequence and returns one value. For a more detailed description of the difference between many to one, many to many RNNs etc. have a look at this Stack Exchange answer.
How can a “many to one” neural network be used for time series prediction? A “many to one” RNN can be seen as a function f, that takes as input n steps of a time series, and outputs a value. An RNN can, for instance, be trained to intake the past 4 values of a time series and output a prediction of the next value.
Let X be a time series and Xt the value of that time series at time t, then:
f(Xt-3, Xt-2, Xt-1, Xt) = Xpredictedt+1
The function f is composed of 4 RNN cells and can be represented as following:
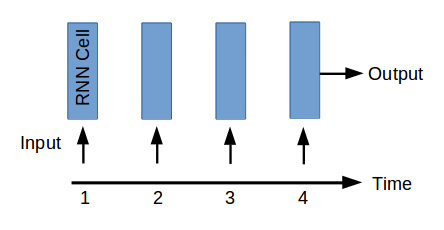
If more than one prediction is needed (which is often the case) then the value predicted can be used as input and a new prediction can be made. Following is a representation of 3 runs through a RNN model to produce predictions for 3 steps in the future.
f(Xt-2, Xt-1, Xt, Xpredictedt+1) = Xpredictedt+2
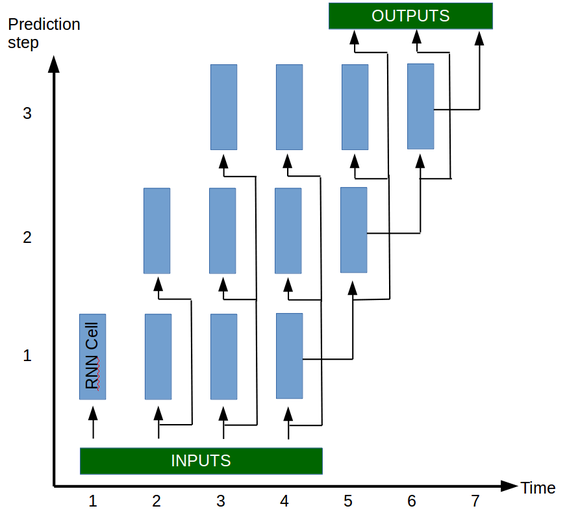
As you can see, the basis of the prediction model f is a single unit, the RNN cell, that takes as input Xt and the state of the network (not represented in these graphs for clarity) and ouputs a single value (discarded unless all the input values have been input to the cell). The function f described above is evaluated by running the cell of the network 4 times, each time with a new input and the state output from the previous step.
Extending the many to one neural network
There are multiple reasons why this architecture might not be the best for time series prediction, compounding errors is one. However, in my opinion, there is a more important reason as to why it might not be the best method. In a time series prediction problem there are intuitively two distinct tasks. Human beings predicting a time series would proceed by looking at the known values of the past, and use their understanding of what happened in the past to predict the future values. These two tasks require two distinct skillsets:
- The ability to look at the past values and create an idea of the state of the system in the present.
- The ability to use that understanding of the state of the system to predict how the system will evolve in the future.
By using a single RNN cell in our model we are asking it to be capable of both memorising important events of the past and using these events to predict future values. This is the reasoning behind considering the encoder-decoder for time series prediction. Rather than having a single multi-tasking cell, the model will use two specialised cells. One for memorising important events of the past (encoder) and one for converting the important events into a prediction of the future (decoder).
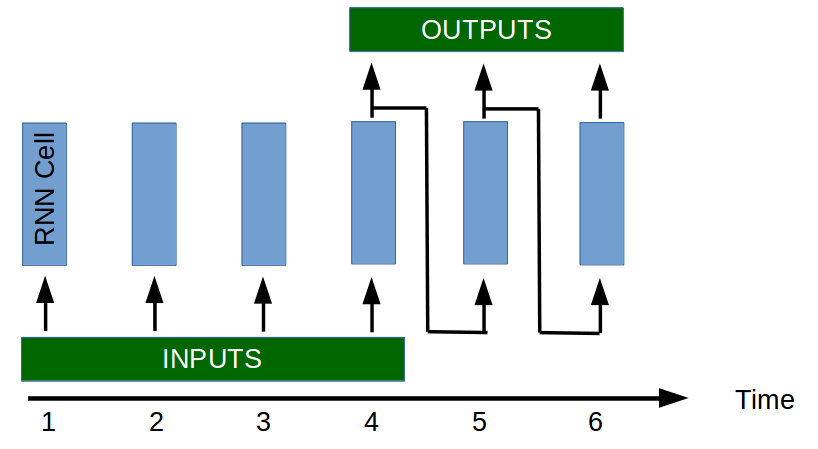
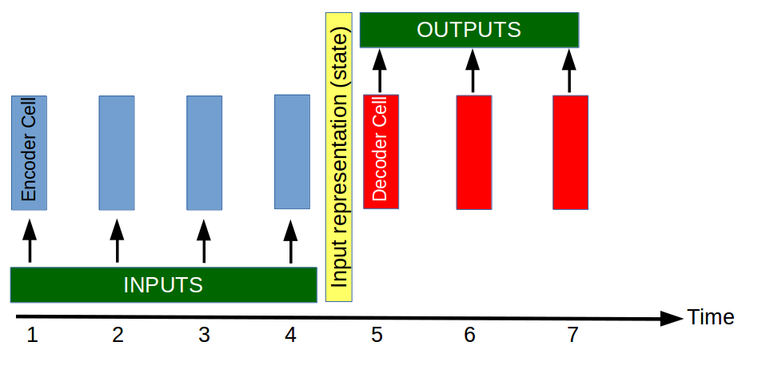
This idea of having two cells (an encoder and a decoder) is used in other maching learning tasks, the most prominent being perhaps machine translation. In machine translation, the idea behind having two separate tasks is even clearer. Let’s say we’re creating a system that translates French to English. First we need an element (encoder) that is capable of understanding French, its only task is to understand the input sentence and create a representation of what that sentence means. Then we need a second system (decoder) that is capable of converting a representation of the meaning of the French sentence to a sentence in English with the same meaning. Instead of having a super intelligent cell that can understand French and speak English, we can create two cells, the encoder understands French but cannot speak English and the decoder knows how to speak English but cannot understand French. By working together, these specialised cells outperform the super cell.
How to create an encoder-decoder for time series prediction in Keras?
Now that we have an explanation as to why an encoder-decoder might work, we are going to implement one.
We will be training our model on an artificially generated dataset. Our time series will be composed of the sum of 2 randomly generated sine waves (random amplitude, frequency, phase and offset). The idea to use such a dataset came from Guillaume Chevalier (link in the beginning of the notebook) although I rewrote his functions to suit my needs. The dataset generators will be imported from utils.py at the root of this repository. This code is python 3 compatible (some things won’t work in python 2).
Import modules/packages
Let’s start by importing some packages and defining a couple of utility functions.
The utility functions (random_sine and plot_predictions) are mostly unimportant for undertanding the encoder/decoder. If you wish, you can jump to the next section.
import keras
import numpy as np
from matplotlib import pyplot as plt
# This section contains code modified licensed under the MIT License:
# Copyright (c) 2017 Guillaume Chevalier # For more information, visit:
# https://github.com/guillaume-chevalier/seq2seq-signal-prediction
# https://github.com/guillaume-chevalier/seq2seq-signal-prediction/blob/master/LICENSE
"""Contains functions to generate artificial data for predictions as well as a function to plot predictions."""
def random_sine(batch_size, steps_per_epoch,
input_sequence_length, target_sequence_length,
min_frequency=0.1, max_frequency=10,
min_amplitude=0.1, max_amplitude=1,
min_offset=-0.5, max_offset=0.5,
num_signals=3, seed=43):
"""Produce a batch of signals.
The signals are the sum of randomly generated sine waves.
Arguments
---------
batch_size: Number of signals to produce.
steps_per_epoch: Number of batches of size batch_size produced by the
generator.
input_sequence_length: Length of the input signals to produce.
target_sequence_length: Length of the target signals to produce.
min_frequency: Minimum frequency of the base signals that are summed.
max_frequency: Maximum frequency of the base signals that are summed.
min_amplitude: Minimum amplitude of the base signals that are summed.
max_amplitude: Maximum amplitude of the base signals that are summed.
min_offset: Minimum offset of the base signals that are summed.
max_offset: Maximum offset of the base signals that are summed.
num_signals: Number of signals that are summed together.
seed: The seed used for generating random numbers
Returns
-------
signals: 2D array of shape (batch_size, sequence_length)
"""
num_points = input_sequence_length + target_sequence_length
x = np.arange(num_points) * 2*np.pi/30
while True:
# Reset seed to obtain same sequences from epoch to epoch
np.random.seed(seed)
for _ in range(steps_per_epoch):
signals = np.zeros((batch_size, num_points))
for _ in range(num_signals):
# Generate random amplitude, frequence, offset, phase
amplitude = (np.random.rand(batch_size, 1) *
(max_amplitude - min_amplitude) +
min_amplitude)
frequency = (np.random.rand(batch_size, 1) *
(max_frequency - min_frequency) +
min_frequency)
offset = (np.random.rand(batch_size, 1) *
(max_offset - min_offset) +
min_offset)
phase = np.random.rand(batch_size, 1) * 2 * np.pi
signals += amplitude * np.sin(frequency * x + phase)
signals = np.expand_dims(signals, axis=2)
encoder_input = signals[:, :input_sequence_length, :]
decoder_output = signals[:, input_sequence_length:, :]
# The output of the generator must be ([encoder_input, decoder_input], [decoder_output])
decoder_input = np.zeros((decoder_output.shape[0], decoder_output.shape[1], 1))
yield ([encoder_input, decoder_input], decoder_output)
def plot_prediction(x, y_true, y_pred):
"""Plots the predictions.
Arguments
---------
x: Input sequence of shape (input_sequence_length,
dimension_of_signal)
y_true: True output sequence of shape (input_sequence_length,
dimension_of_signal)
y_pred: Predicted output sequence (input_sequence_length,
dimension_of_signal)
"""
plt.figure(figsize=(12, 3))
output_dim = x.shape[-1]
for j in range(output_dim):
past = x[:, j]
true = y_true[:, j]
pred = y_pred[:, j]
label1 = "Seen (past) values" if j==0 else "_nolegend_"
label2 = "True future values" if j==0 else "_nolegend_"
label3 = "Predictions" if j==0 else "_nolegend_"
plt.plot(range(len(past)), past, "o--b",
label=label1)
plt.plot(range(len(past),
len(true)+len(past)), true, "x--b", label=label2)
plt.plot(range(len(past), len(pred)+len(past)), pred, "o--y",
label=label3)
plt.legend(loc='best')
plt.title("Predictions v.s. true values")
plt.show()
if __name__ == '__main__':
# This is an example of the plot function and the signal generator
from matplotlib import pyplot as plt
gen = random_sine(3, 3, 15, 15)
for i, data in enumerate(gen):
input_seq, output_seq = data
for j in range(input_seq.shape[0]):
plot_prediction(input_seq[j, :, :],
output_seq[j, :, :],
output_seq[j, :, :])
if i > 2:
break
Hyperparameters and model configuration
This model uses a Gated Recurrent Unit (GRU). Other units (LSTM) would also work with a few modifications to the code.
keras.backend.clear_session()
# Number of hidden neuros in each layer of the encoder and decoder
layers = [35, 35]
learning_rate = 0.01
decay = 0 # Learning rate decay
# Other possible optimiser "sgd" (Stochastic Gradient Descent)
optimiser = keras.optimizers.Adam(lr=learning_rate, decay=decay)
# The dimensionality of the input at each time step. In this case a 1D signal.
num_input_features = 1
# The dimensionality of the output at each time step. In this case a 1D signal.
num_output_features = 1
# There is no reason for the input sequence to be of same dimension as the ouput sequence.
# For instance, using 3 input signals: consumer confidence, inflation and house prices to predict the future house prices.
# Other loss functions are possible, see Keras documentation.
loss = "mse"
# Regularisation isn't really needed for this application
lambda_regulariser = 0.000001 # Will not be used if regulariser is None
regulariser = None # Possible regulariser: keras.regularizers.l2(lambda_regulariser)
# batch_size * steps_per_epoch = total number of training examples
batch_size = 512
steps_per_epoch = 200
epochs = 15
input_sequence_length = 15 # Length of the sequence used by the encoder
target_sequence_length = 15 # Length of the sequence predicted by the decoder
num_steps_to_predict = 20 # Length to use when testing the model
# The number of random sine waves the compose the signal. The more sine waves, the harder the problem.
num_signals = 2
Create model
Create encoder
The encoder is first created by instantiating a graph, which is a description of the operations applied to the tensors (that will later hold the data). This is common among many neural network frameworks.
# Define an input sequence.
encoder_inputs = keras.layers.Input(shape=(None, num_input_features))
# Create a list of RNN Cells, these are then concatenated into a single layer
# with the RNN layer.
encoder_cells = []
for hidden_neurons in layers:
encoder_cells.append(keras.layers.GRUCell(hidden_neurons,
kernel_regularizer=regulariser,
recurrent_regularizer=regulariser,
bias_regularizer=regulariser))
encoder = keras.layers.RNN(encoder_cells, return_state=True)
encoder_outputs_and_states = encoder(encoder_inputs)
# Discard encoder outputs and only keep the states.
# The outputs are of no interest to us, the encoder's
# job is to create a state describing the input sequence.
encoder_states = encoder_outputs_and_states[1:]
Create decoder
The decoder is created similarly to the encoder
# The decoder input will be set to zero (see random_sine function of the utils module).
# Do not worry about the input size being 1, I will explain that in the next cell.
decoder_inputs = keras.layers.Input(shape=(None, 1))
decoder_cells = []
for hidden_neurons in layers:
decoder_cells.append(keras.layers.GRUCell(hidden_neurons,
kernel_regularizer=regulariser,
recurrent_regularizer=regulariser,
bias_regularizer=regulariser))
decoder = keras.layers.RNN(decoder_cells, return_sequences=True, return_state=True)
# Set the initial state of the decoder to be the ouput state of the encoder.
# This is the fundamental part of the encoder-decoder.
decoder_outputs_and_states = decoder(decoder_inputs, initial_state=encoder_states)
# Only select the output of the decoder (not the states)
decoder_outputs = decoder_outputs_and_states[0]
# Apply a dense layer with linear activation to set output to correct dimension
# and scale (tanh is default activation for GRU in Keras, our output sine function can be larger then 1)
decoder_dense = keras.layers.Dense(num_output_features,
activation='linear',
kernel_regularizer=regulariser,
bias_regularizer=regulariser)
decoder_outputs = decoder_dense(decoder_outputs)
Create model and compile
A notable detail here, are the inputs to the model. The train model has two inputs : encoder_inputs and decoder_inputs. What encoder_inputs should be is clear, the encoder_inputs should hold the input series. But what about the decoder inputs?
In machine translation applications (see “A ten minute introduction to sequence-to-sequence learning in keras”) something called teacher forcing is used. In teacher forcing, the input to the decoder during training is the target sequence shifted by 1. This supposedly helps the decoder learn and is an effective method for machine translation. I tested teacher forcing for sequence prediction and the results were bad. I am not entirely sure why this is the case, my intuition is that unlike machine translation, if you feed the decoder the correct sequence shifted by one, your model becomes “lazy” because it only has to look at the value input in the step before and apply a small modification to it. In other words, the gradients of the truncated back propagation beyond the n-1 step will be very small and the model will develop a short memory. However, if the input to the decoder is 0, it forces the model to really memorize the values that are fed to the encoder since it has nothing else to work on. In some sense, teacher forcing might artificially induce vanishing gradients.
If you look into the random_sine function defined earlier, you will see that the decoder input is simply set to zero. You may be asking yourselves why the decoder has an input at all if it’s set to zero… The reason is simple, Keras RNNs must take an input value alongside the state vector.
# Create a model using the functional API provided by Keras.
# The functional API is great, it gives an amazing amount of freedom in architecture of your NN.
# A read worth your time: https://keras.io/getting-started/functional-api-guide/
model = keras.models.Model(inputs=[encoder_inputs, decoder_inputs], outputs=decoder_outputs)
model.compile(optimizer=optimiser, loss=loss)
Fit model to data
I like using the fit_generator in Keras. In this case it’s not really useful/necessary since my training examples easily fit into memory. In cases when the training data doesn’t fit into memory, the fit_generator is definitely the way to go. A standard python generator is usually fine for the fit_generator function, however, Keras provides a nice class keras.utils.Sequence that you can inherit from to create your own generator. This is a requirement to guarantee that the elements of the generator are only selected once in the case of multiprocessing (which isn’t guaranteed with the standard generator). A simple example of using the data generators in Keras is “A detailed example of how to use data generators with Keras” by Shervine Amidi.
# random_sine returns a generator that produces batches of training samples ([encoder_input, decoder_input], decoder_output)
# You can play with the min max frequencies of the sine waves, the number of sine waves that are summed etc...
# Another interesing exercise could be to see whether the model generalises well on sums of 3 signals if it's only been
# trained on sums of 2 signals...
train_data_generator = random_sine(batch_size=batch_size,
steps_per_epoch=steps_per_epoch,
input_sequence_length=input_sequence_length,
target_sequence_length=target_sequence_length,
min_frequency=0.1, max_frequency=10,
min_amplitude=0.1, max_amplitude=1,
min_offset=-0.5, max_offset=0.5,
num_signals=num_signals, seed=1969)
model.fit_generator(train_data_generator, steps_per_epoch=steps_per_epoch, epochs=epochs)
It is now possible to use this model to make predictions:
test_data_generator = random_sine(batch_size=1000,
steps_per_epoch=steps_per_epoch,
input_sequence_length=input_sequence_length,
target_sequence_length=target_sequence_length,
min_frequency=0.1, max_frequency=10,
min_amplitude=0.1, max_amplitude=1,
min_offset=-0.5, max_offset=0.5,
num_signals=num_signals, seed=2000)
(x_encoder_test, x_decoder_test), y_test = next(test_data_generator) # x_decoder_test is composed of zeros.
y_test_predicted = model.predict([x_encoder_test, x_decoder_test])
A limitation of using this model to make the predictions is that we can only predict a sequence of same length as the training data. This can be a problem if we want to predict less or more than the training sequence lengths. In the next section I will show how to create “prediction” models that allow to predict sequences of arbitrary length.
Create “prediction” models
When using the encoder-decoder to predict a sequence of arbitrary length, the encoder first encodes the entire input sequence. The state of the encoder is then fed to the decoder which then produces the output sequence sequentially. Although a new model is being created with the keras.models.Model class, the input and output tensors of the model are the same as those used during training, hence the weights of the layers applied to the tensors are preserved.
As you will see, creating the prediction models also gives the ability to inspect the state of the model at different points throughout the prediction process. We could study how the encoder creates a representation of the input data. For instance, how does the model represent the offset? Or the frequency? Does it decompose the signal into it’s constituent sine waves and represent them as different dimensions of the state vector? These are very interesting questions for another time.
encoder_predict_model = keras.models.Model(encoder_inputs,
encoder_states)
decoder_states_inputs = []
# Read layers backwards to fit the format of initial_state
# For some reason, the states of the model are order backwards (state of the first layer at the end of the list)
# If instead of a GRU you were using an LSTM Cell, you would have to append two Input tensors since the LSTM has 2 states.
for hidden_neurons in layers[::-1]:
# One state for GRU
decoder_states_inputs.append(keras.layers.Input(shape=(hidden_neurons,)))
decoder_outputs_and_states = decoder(
decoder_inputs, initial_state=decoder_states_inputs)
decoder_outputs = decoder_outputs_and_states[0]
decoder_states = decoder_outputs_and_states[1:]
decoder_outputs = decoder_dense(decoder_outputs)
decoder_predict_model = keras.models.Model((
[decoder_inputs] + decoder_states_inputs,
[decoder_outputs] + decoder_states)
# Let's define a small function that predicts based on the trained encoder and decoder models
def predict(x, encoder_predict_model, decoder_predict_model, num_steps_to_predict):
"""Predict time series with encoder-decoder.
Uses the encoder and decoder models previously trained to predict the next
num_steps_to_predict values of the time series.
Arguments
---------
x: input time series of shape (batch_size, input_sequence_length, input_dimension).
encoder_predict_model: The Keras encoder model.
decoder_predict_model: The Keras decoder model.
num_steps_to_predict: The number of steps in the future to predict
Returns
-------
y_predicted: output time series for shape (batch_size, target_sequence_length,
ouput_dimension)
"""
y_predicted = []
# Encode the values as a state vector
states = encoder_predict_model.predict(x)
# The states must be a list
if not isinstance(states, list):
states = [states]
# Generate first value of the decoder input sequence
decoder_input = np.zeros((x.shape[0], 1, 1))
for _ in range(num_steps_to_predict):
outputs_and_states = decoder_predict_model.predict(
[decoder_input] + states, batch_size=batch_size)
output = outputs_and_states[0]
states = outputs_and_states[1:]
# add predicted value
y_predicted.append(output)
return np.concatenate(y_predicted, axis=1)
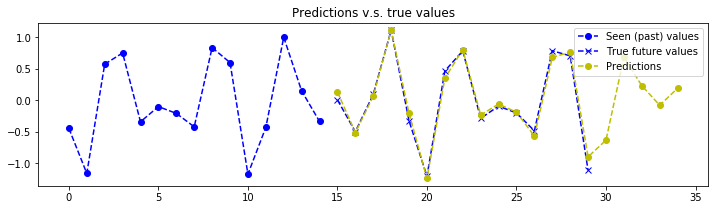
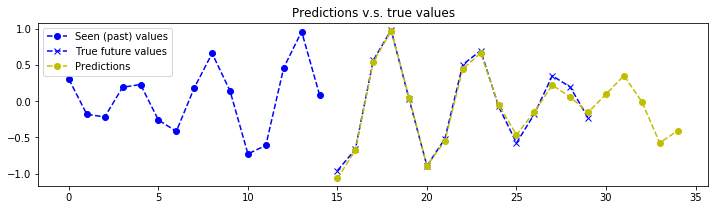
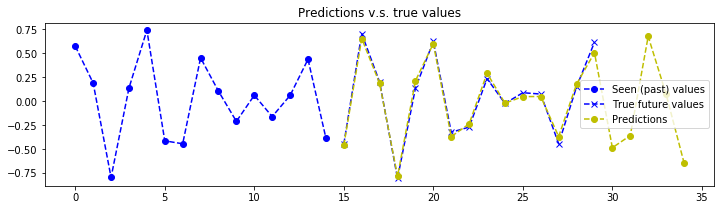
The aim of this tutorial isn’t to present how to evaluate the model or investigate the training. We could plot evaluation metrics such as RMSE over time, compare train and test batches for overfitting, produce validation and learning curves to analyse the effect of the number of epochs or training examples, have fun playing with tensorboard etc… We would need at least a whole other post for this. However, let’s at least make sure that our model can predict correctly… Ask the generator to produce a batch of samples, don’t forget to set the seed to something other than what was used for training or you will be testing on train data. The next function asks the generator to produce it’s first batch.
test_data_generator = random_sine(batch_size=1000,
steps_per_epoch=steps_per_epoch,
input_sequence_length=input_sequence_length,
target_sequence_length=target_sequence_length,
min_frequency=0.1, max_frequency=10,
min_amplitude=0.1, max_amplitude=1,
min_offset=-0.5, max_offset=0.5,
num_signals=num_signals, seed=2000)
(x_test, _), y_test = next(test_data_generator)
y_test_predicted = predict(x_test, encoder_predict_model, decoder_predict_model, num_steps_to_predict)
# Select 10 random examples to plot
indices = np.random.choice(range(x_test.shape[0]), replace=False, size=10)
for index in indices:
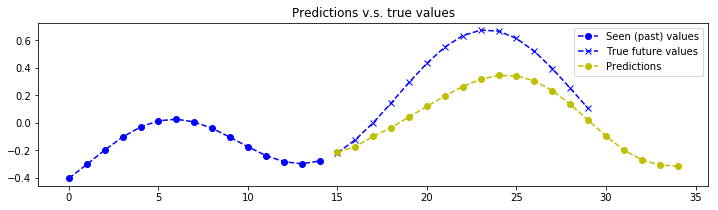
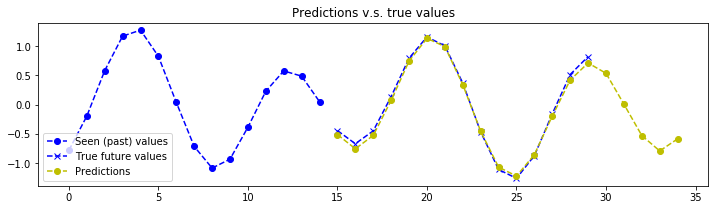
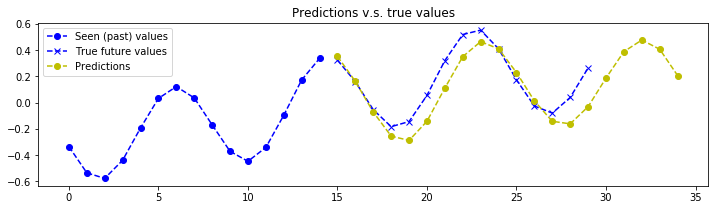
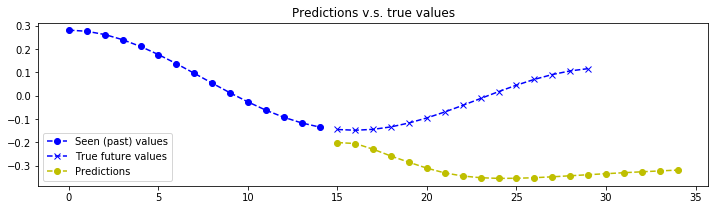
plot_prediction(x_test[index, :, :], y_test[index, :, :], y_test_predicted[index, :, :])
# The model seems to struggle on very low frequency signals. But that makes sense, the model doesn't see enough of the signal to make a good estimation of the frequency components.
train_data_generator = random_sine(batch_size=1000,
steps_per_epoch=steps_per_epoch,
input_sequence_length=input_sequence_length,
target_sequence_length=target_sequence_length,
min_frequency=0.1, max_frequency=10,
min_amplitude=0.1, max_amplitude=1,
min_offset=-0.5, max_offset=0.5,
num_signals=num_signals, seed=1969)
(x_train, _), y_train = next(train_data_generator)
y_train_predicted = predict(x_train, encoder_predict_model, decoder_predict_model, num_steps_to_predict)
# Select 10 random examples to plot
indices = np.random.choice(range(x_train.shape[0]), replace=False, size=10)
for index in indices:
plot_prediction(x_train[index, :, :], y_train[index, :, :], y_train_predicted[index, :, :])
Next steps & Discussion
There are many things that could be done to either extend or improve this model. Here are a few ideas.
- There’s no reason why the encoder and decoder should have the same complexity or the same number of layers. As well as doing a simple hyper parameter search, it could be interesting to implement a model with different encoder and decoder sizes. To do this, one would have to add a dense layer after retrieving the states of the encoder to transform them into the correct size.
- Encapsulate the encoder-decoder by creating a class with a fit/predict interface. This is actually something I have done, it’s extremely useful as it allows to instantiate seq2seq models as easily as one would instantiate a scikit learn model.
- Add the ability to add context vectors to the state output by the encoder. The encoder is able to produce an input vector for the decoder based on the time series. It is possible to add constant features to the model by duplicating them at each input timestep. However, adding the ability to extend the encoder output state with a constant vector that represents context might also be a good idea (for example, if you’re predicting the evolution of housing prices, you might want to tell your model which geographical area you are in, since prices might not evolve in the same manner depending on location). This is not the attention mechanism often used in NLP that also produces what is called a context vector(a context vector that is updated at each step of the decoder). But since adding attention to NLP seq2seq applications has hugely improved state of the art. It might also be worth looking into attention for sequence prediction.
- As described above, study how the encoder creates a representation of the input sequence by looking at the state vector.
- It appears that our model struggles on signals that have low frequency, one explanation might be that the model must “see” at least a certain number of periods to determine the frequency of the signal. An interesting questions to answer might be: How many periods of the constituent signals are required for the model to be accurate?
- Although our model was only train on an output sequence of length 15, it appears to be able to predict beyond that limit, this is something we can exploit with the prediction models.
Thanks for reading 🙂
I welcome questions or comments, you can also find me on LinkedIn.
Author: Luke Tonin
LinkedIn: https://linkedin.com/in/luketonin
Github: https://github.com/LukeTonin/